지난번에는 스프링 부트에서 GPT API를 연동하고 질문을 던지고 GPT 답변을 받는 방법을 알아보았다.
이번에는 파인 튜닝 데이터를 활용해 특정 작업에 맞춰 조정된 GPT 모델을 만드는 방법을 알아보겠다.
일단 파인튜닝이 무엇인가에 대해 간단히 알아보자.
Fine-tuning은 '미세 조정'이라는 뜻으로 딥 러닝에서 사전 훈련된 모델을 새로운 데이터에 대해 훈련시켜 해당 데이터에 대한 작업에 좀 더 적합하게 조정하는 방식이다.
Fine-tuning (deep learning) - Wikipedia
Fine-tuning (deep learning) - Wikipedia
From Wikipedia, the free encyclopedia Machine learning technique In deep learning, fine-tuning is an approach to transfer learning in which the weights of a pre-trained model are trained on new data.[1] Fine-tuning can be done on the entire neural network,
en.wikipedia.org
즉 GPT 파인 튜닝은 훈련된 GPT 모델에게 새로운 데이터를 제공해 해당 데이터에 적합하게 GPT 모델을 미세 조정한다는 것이다.
이를 위해서는 우선 훈련시킬 데이터를 준비할 필요가 있다.
여기서 파인튜닝을 위한 데이터는 Openai에서 권장하는 데이터 포맷이 있다.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}위 두 포맷이 Openai에서 파인 튜닝을 위한 데이터의 예시로 나타낸 포멧이다.
OpenAI Platform
Explore developer resources, tutorials, API docs, and dynamic examples to get the most out of OpenAI's platform.
platform.openai.com
여기서 사용할 GPT 모델에 따라 데이터셋을 달리 해야 하는데,
내가 사용한 GPT-3.5-turbo 모델같은 경우 Chat Model이기 때문에
prompt 데이터셋이 아닌 message 데이터셋을 적용해야한다고 한다.
실제로 prompt 데이터셋으로 파인 튜닝을 적용하려고 하니 에러 메시지가 전달됐다.
모델에 따라 데이터셋을 활용할 수 있는 사람은 이 글이 필요없기에 처음 파인 튜닝을 진행하는 사람을 기준으로
보편적인 gpt-3.5-turbo모델을 활용한 파인 튜닝을 진행하겠다.
나같은 경우에는 금융 업무를 분류하기 위한 데이터를 만들었다.
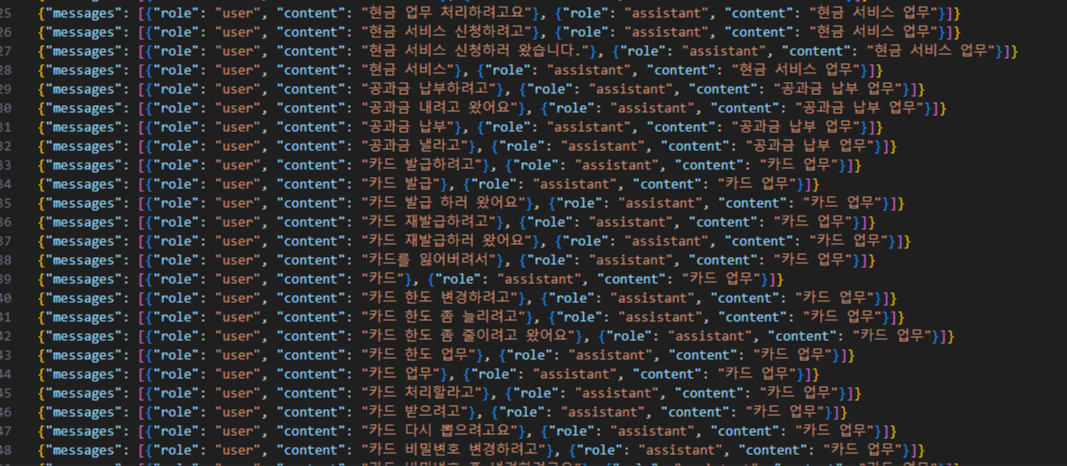
위와 같이 데이터셋을 구현했고, 이는 약 100개가 넘는 데이터셋이다.
파인튜닝을 위해서는 우선 본인 API KEY를 이용해 데이터셋 파일을 OpenAI에 업로드를 해야한다.
파이썬이나 node.js 같은 경우 공식 홈페이지에서 잘 설명이 되어 있으니 확인해보길 바란다.
자바 같은 경우 커뮤니티 라이브러리인 Theo Kanning 님의 라이브러리를 활용한다.
해당 라이브러리의 OpenaiService class를 확인하면
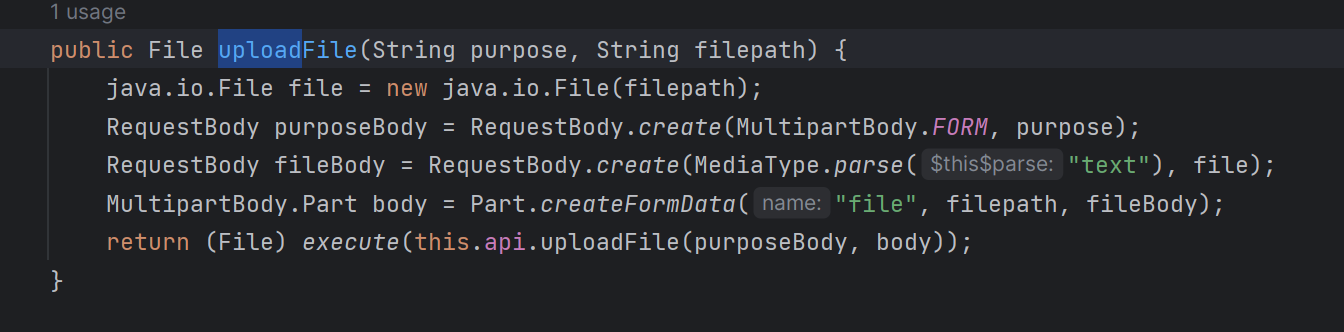
uploadFile이라는 메소드를 확인할 수 있다.
목적과 파일패스를 기입하면 해당 파일을 openai 쪽으로 업로드하는 것이다.
여기서 목적은 'fine-tune', 파일패스는 업로드하려는 데이터셋의 루트를 적어주면 된다.

위와 같이 말이다.
이렇게 되면 Openai쪽으로 파일이 업로드 되는데, 업로드 될 때마다 fileId를 할당받는다.
파인튜닝을 위해서는 이 fileId가 필요하다.
이를 확인하기 위해서는 업로드하는 동시에 print하거나 업로드된 파일목록을 불러오는 메소드인 listFiles()를 통해
확인할 수 있다.
파일을 업로드한다면 fileId를 확인하고 FineTuningJobRequest 객체를 생성한다.
해당 객체는 다음과 같이 구성되어 있다.
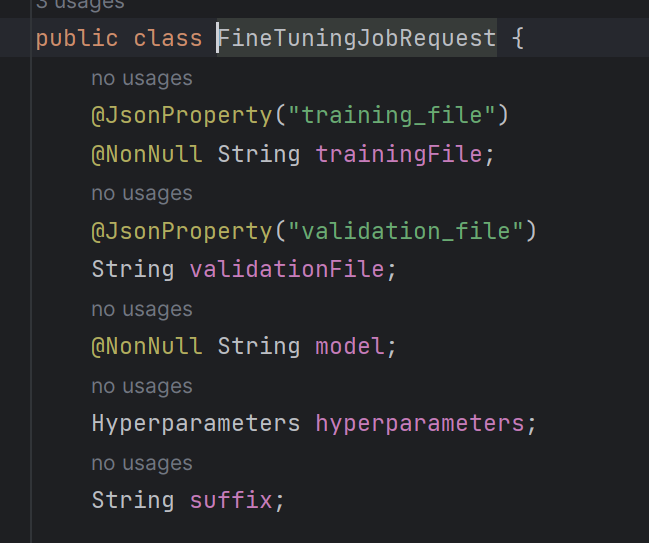
여기서 필수 항목인 trainingFIle과 model을 기입하여 파인튜닝을 실행할 수 있다.

이렇게 작성해 보았다.
업로드한 파일을 트레이닝 파일로 삼고, 트레이닝할 모델은 gpt 3.5 turbo모델로 설정했다.
마지막으로 다음 코드를 작성 및 실행한다.

말 그대로 파인튜닝 작업을 생성하는 것이다.
이렇게 되면 파인튜닝을 진행하게 되는데 이는 OpenAI 홈페이지에서 확인할 수 있다.
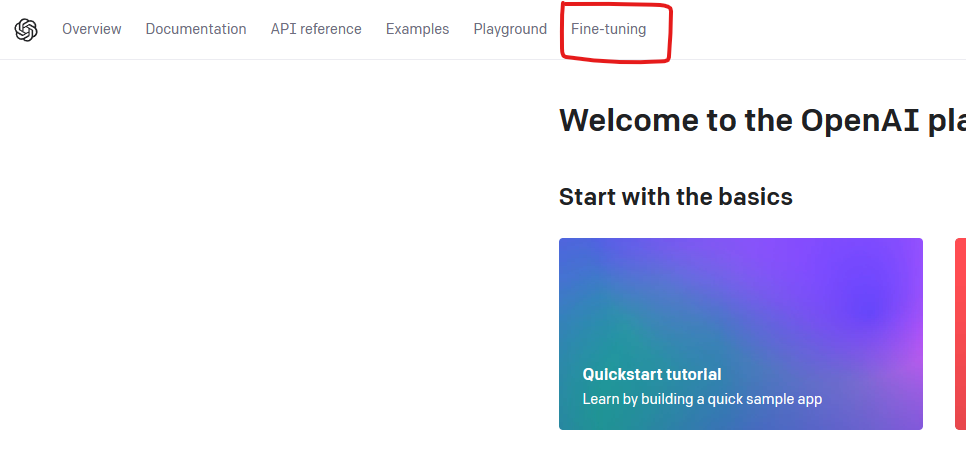
위 탭으로 들어가면 바로 확인 가능하다.
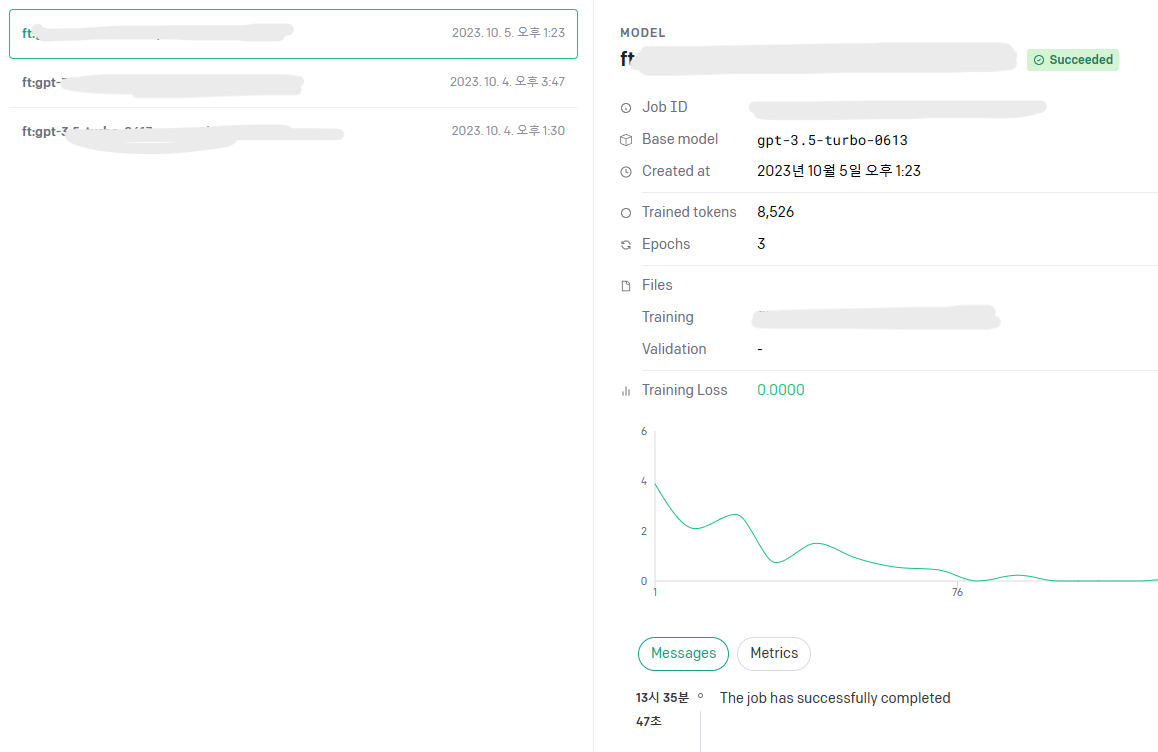
파인튜닝이 완료되기 전에는 저기 Succeeded가 진행 중이라고 표시되는데
모두 완료되면 Succeeded로 전환되고 해당 모델을 사용할 수 있다.
해당 모델을 사용하기 위해서는 지난 번에 API를 활용해 질문을 날릴 때 모델을 설정했던 곳에 모델 이름을 바꿔주면 된다.

이렇게 말이다.
이러면 파인 튜닝된 모델을 활용해 쿼리를 날릴 수 있고, 학습한 데이터로 가중치를 미세 조정한 gpt-3.5-turbo 모델의 답변을 받을 수 있다.
이렇게 스프링 부트에서 자바로 파인 튜닝하는 방법을 알아보았다.
'기타 > GPT' 카테고리의 다른 글
| 스프링 부트에서 GPT API를 통해 Service 이용하기 (0) | 2023.09.27 |
|---|---|
| 스프링 부트에서 GPT API 연동하기 (0) | 2023.09.27 |

